
前言
继上回打so库后朝着全干工程师的道路越走越远,我还只是个入职两个月的 初级工程师 啊喂 !!!希望转正的时候能给个好看点的薪资吧😥
吐槽归吐槽,这回分享一些关于此次爬虫项目的心得…
正文
环境说明
- Anaconda3
- python3.8
- Windows10
- scrapy2.4.1 项目地址:scrapy(github.com) 官方文档:Scrapy 2.5 documentation
这是什么项目?
一个【数据删除】题库爬虫,该题库囊括小学、初中、高中所有学科;因为公司 (白嫖) 精打细算的策略,本人奉命从某个网站爬取题目;为规避纠纷,后文将对部分敏感信息手动打码👉 【数据删除】 ,让我们愉快的开始吧♂
Scrapy框架介绍
流程图
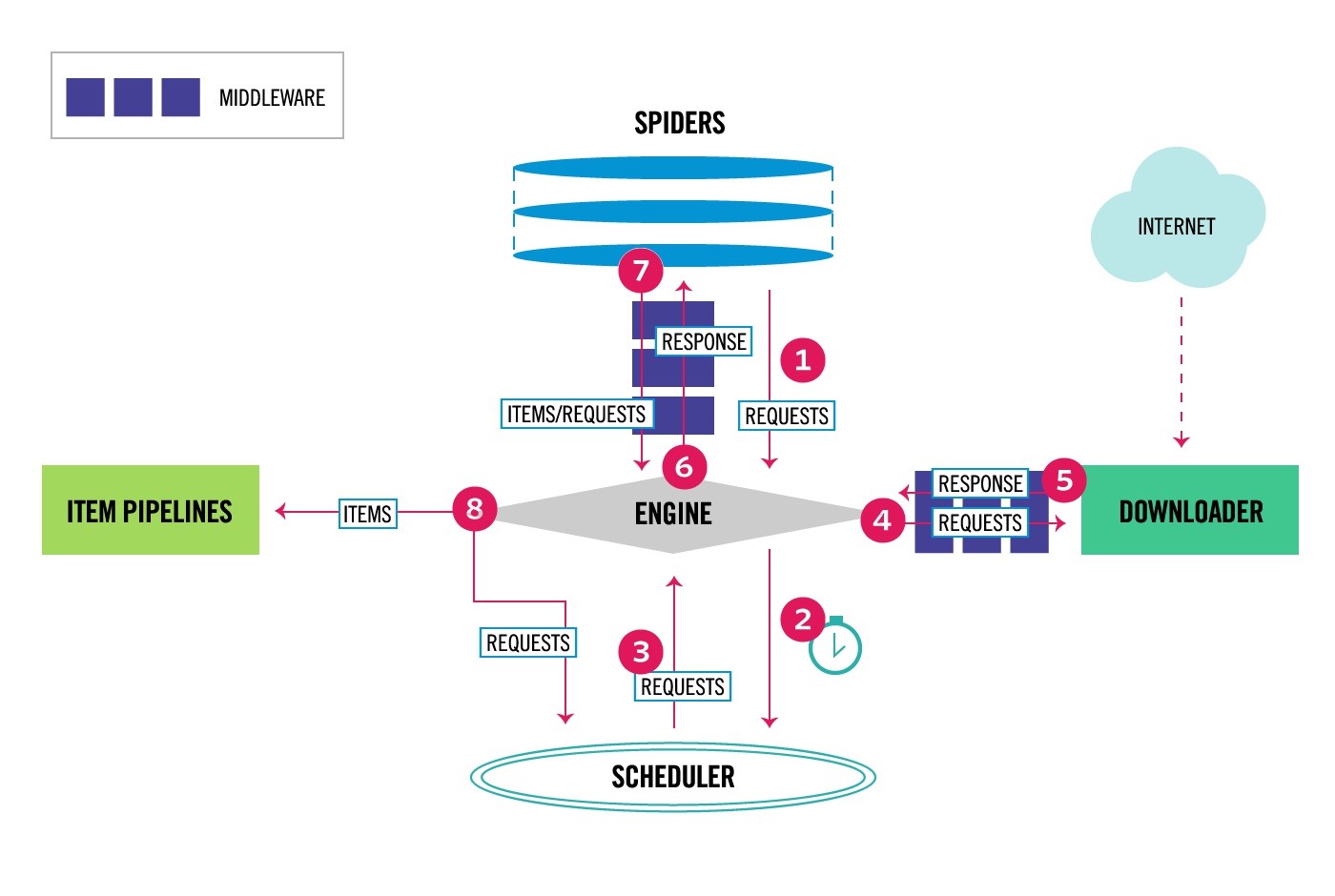
模块说明
items.py
该模块用于定义数据模型,可以把业务实体抽象出来。例如:
import scrapy
class TikuQuestions(scrapy.Item):
"""题库模型"""
question_id = scrapy.Field()
q_period = scrapy.Field()
q_subject = scrapy.Field()
q_difficulty = scrapy.Field()
q_type = scrapy.Field()
q_from = scrapy.Field()
q_year = scrapy.Field()
q_refer_exampapers = scrapy.Field()
q_knowledges = scrapy.Field()
q_description = scrapy.Field()
q_stems = scrapy.Field()
q_answers = scrapy.Field()
q_explanations = scrapy.Field()
q_solutions = scrapy.Field()
q_comment = scrapy.Field()
class TikuExampapers(scrapy.Item):
"""试卷模型"""
exampaper_id = scrapy.Field()
e_press_version = scrapy.Field()
e_from_year = scrapy.Field()
e_to_year = scrapy.Field()
e_period = scrapy.Field()
e_grade = scrapy.Field()
e_name = scrapy.Field()
e_province = scrapy.Field()
e_city = scrapy.Field()
e_subject = scrapy.Field()
e_type = scrapy.Field()
e_text = scrapy.Field()
#########下略#########middlewares.py
包括爬虫中间件与下载中间件,如上图标号4、5处所示,是一个介于 ENGINE 与 DOWNLOADER 的钩子框架,可在request请求发出前对请求做些包装、对response返回时对其中的数据进行预处理,如全局修改代理ip,header等;
下载器中间件(Downloader Middleware)
使用下载器中间件时必须激活这个中间件,方法是在 settings.py 文件中设置 DOWNLOADER_MIDDLEWARES 这个字典,格式类似如下:
DOWNLOADERMIDDLEWARES = {
'myproject.middlewares.Custom_A_DownloaderMiddleware': 543,
'myproject.middlewares.Custom_B_DownloaderMiddleware': 643,
'myproject.middlewares.Custom_B_DownloaderMiddleware': None,
}P.S. 数字越小,越靠近 ENGINE (引擎),数字越大越靠近 DOWNLOADER (下载器),所以数字越小
process_request()越优先处理;数字越大process_response()越优先处理;若需要关闭某个中间件直接设为None即可;
自定义下载器中间件
有时我们需要编写自己的一些下载器中间件,如使用代理,更换user-agent等,对于请求(request)的中间件实现 process_request(request, spider);对于处理回复(response)中间件实现 process_response(request, response, spider);以及异常处理实现 process_exception(request, exception, spider);
process_request(*request*, *spider*)
每当scrapy进行一个request请求时,这个方法被调用。通常它可以返回1.None 2.Response对象 3.Request对象 4.抛出IgnoreRequest对象;
通常返回None较常见,它会继续执行爬虫下去。其他返回情况参考 这里
例如下面2个例子是更换user-agent和代理ip的下载中间件;
user-agent中间件
对于某些限制单个UA并发量的网站,相同的IP切换不同UA即可规避,比如哔哩哔哩的api;
from faker import Faker
# 固定user-agent
class UserAgent_Middleware():
def process_request(self, request, spider):
f = Faker()
agent = f.firefox()
request.headers['User-Agent'] = agent
# 随机选择user-agent
class RandomUserAgentMiddleware(object):
def process_request(self, request, spider):
rand_use = random.choice(USER_AGENT_LIST) # 见 我的常用User-Agent
if rand_use:
request.headers.setdefault('User-Agent', rand_use)代理ip中间件
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
# 'Connection': 'close'
}
class Proxy_Middleware():
def __init__(self):
self.s = requests.session()
# 请求一个代理ip
def process_request(self, request, spider):
try:
xdaili_url = spider.settings.get('XDAILI_URL')
r = self.s.get(xdaili_url, headers= headers)
proxy_ip_port = r.text
request.meta['proxy'] = 'http://' + proxy_ip_port
except requests.exceptions.RequestException:
print('***get xdaili fail!')
spider.logger.error('***get xdaili fail!')
def process_response(self, request, response, spider):
if response.status != 200:
try:
xdaili_url = spider.settings.get('XDAILI_URL')
r = self.s.get(xdaili_url, headers= headers)
proxy_ip_port = r.text
request.meta['proxy'] = 'http://' + proxy_ip_port
except requests.exceptions.RequestException:
print('***get xdaili fail!')
spider.logger.error('***get xdaili fail!')
return request
return response
def process_exception(self, request, exception, spider):
try:
xdaili_url = spider.settings.get('XDAILI_URL')
r = self.s.get(xdaili_url, headers= headers)
proxy_ip_port = r.text
request.meta['proxy'] = 'http://' + proxy_ip_port
except requests.exceptions.RequestException:
print('***get xdaili fail!')
spider.logger.error('***get xdaili fail!')
return request**遇到验证码的处理方法 **
同样有时我们会遇到输入验证码的页面,除了自动识别验证码之外,还可以重新请求(前提是使用了代理ip),只需在spider中禁止过滤:
def parse(self, response):
result = response.text
if re.search(r'make sure you\'re not a robot', result):
self.logger.error('check时ip被限制! asin为: {0}'.format(origin_asin))
print('check时ip被限制! asin为: {0}'.format(origin_asin))
response.request.meta['dont_filter'] = True
return response.request(url)重试中间件
有时使用代理会被远程拒绝或超时等错误,这时我们需要换代理ip重试,重写 scrapy.downloadermiddlewares.retry.RetryMiddleware :
from scrapy.downloadermiddlewares.retry import RetryMiddleware
from scrapy.utils.response import response_status_message
class My_RetryMiddleware(RetryMiddleware):
def process_response(self, request, response, spider):
if request.meta.get('dont_retry', False):
return response
if response.status in self.retry_http_codes:
reason = response_status_message(response.status)
try:
xdaili_url = spider.settings.get('XDAILI_URL')
r = requests.get(xdaili_url)
proxy_ip_port = r.text
request.meta['proxy'] = 'https://' + proxy_ip_port
except requests.exceptions.RequestException:
print('获取讯代理ip失败!')
spider.logger.error('获取讯代理ip失败!')
return self._retry(request, reason, spider) or response
return response
def process_exception(self, request, exception, spider):
if isinstance(exception, self.EXCEPTIONS_TO_RETRY) and not request.meta.get('dont_retry', False):
try:
xdaili_url = spider.settings.get('XDAILI_URL')
r = requests.get(xdaili_url)
proxy_ip_port = r.text
request.meta['proxy'] = 'https://' + proxy_ip_port
except requests.exceptions.RequestException:
print('获取讯代理ip失败!')
spider.logger.error('获取讯代理ip失败!')
return self._retry(request, exception, spider)scrapy中对接selenium
from scrapy.http import HtmlResponse
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from gp.configs import *
class ChromeDownloaderMiddleware(object):
def __init__(self):
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 设置无头
if CHROME_PATH:
options.binary_location = CHROME_PATH
if CHROME_DRIVER_PATH:
self.driver = webdriver.Chrome(chrome_options=options, executable_path=CHROME_DRIVER_PATH) # 初始化Chrome驱动
else:
self.driver = webdriver.Chrome(chrome_options=options) # 初始化Chrome驱动
def __del__(self):
self.driver.close()
def process_request(self, request, spider):
try:
print('Chrome driver begin...')
self.driver.get(request.url) # 获取网页链接内容
return HtmlResponse(url=request.url, body=self.driver.page_source, request=request, encoding='utf-8', status=200)# 返回HTML数据
except TimeoutException:
return HtmlResponse(url=request.url, request=request, encoding='utf-8', status=500)
finally:
print('Chrome driver end...')process_response(*request*, *response*, *spider*)
当请求发出去返回时这个方法会被调用,它会返回 1.Response对象 2.Request对象 3.抛出IgnoreRequest对象:
若返回Response对象,它会被下个中间件中的
process_response()处理;若返回Request对象,中间链停止,然后返回的Request会被重新调度下载;
抛出IgnoreRequest,回调函数 Request.errback将会被调用处理,若没处理,将会忽略;
process_exception(*request*, *exception*, *spider*)
当下载处理模块或process_request()抛出一个异常(包括IgnoreRequest异常)时,该方法被调用;
通常返回None,它会一直处理异常;
from_crawler(*cls*, *crawler*)
这个类方法通常是访问settings和signals的入口函数:
@classmethod
def from_crawler(cls, crawler):
return cls(
mysql_host = crawler.settings.get('MYSQL_HOST'),
mysql_db = crawler.settings.get('MYSQL_DB'),
mysql_user = crawler.settings.get('MYSQL_USER'),
mysql_pw = crawler.settings.get('MYSQL_PW')
)scrapy自带下载器中间件
以下中间件是scrapy默认的下载器中间件,通过重写自定义属于自己的中间件吧~
{
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
}P.S. scrapy自带中间件请参考 这里
Spider中间件(Spider Middleware)
如文章第一张图所示,spider中间件用于处理response及spider生成的item和Request;
注意:从上图看到第1步是没经过spider Middleware的
启动spider中间件必须先开启settings中的设置:
SPIDER_MIDDLEWARES = {
'myproject.middlewares.CustomSpiderMiddleware': 543,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': None,
}数字越小越靠近 ENGINE (引擎),process_spider_input() 优先处理,数字越大越靠近 SPIDER ,process_spider_output() 优先处理,关闭用None;
编写自定义spider中间件
process_spider_input(*response*, *spider*)
当response通过spider中间件时,这个方法被调用,返回None;
process_spider_output(*response*, *result*, *spider*)
当spider处理response后返回result时,这个方法被调用,必须返回Request或Item对象的可迭代对象,一般返回result;
process_spider_exception(*response*, *exception*, *spider*)
当spider中间件抛出异常时,这个方法被调用,返回None或可迭代对象的Request、dict、Item;
pipelines.py
爬虫管道,它可以实现清理html数据、验证爬取的数据、去重并丢弃、将爬取的结果保存到数据库中或文件中,其中传递的item是字典类型;
跟middleware同理,需要在settings中启用:
ITEM_PIPELINES = {
'tika.pipelines.MySQLPipeline': 100,
}优先级数字越小越先执行,执行完毕传给下一个pipeline;
将爬取数据存入MySQL数据库
class MySQLPipeline(object):
def open_spider(self, spider):
db = spider.settings.get('MYSQL_DB_NAME')
host = spider.settings.get('MYSQL_HOST')
port = spider.settings.get('MYSQL_PORT')
user = spider.settings.get('MYSQL_USER')
passwd = spider.settings.get('MYSQL_PASSWORD')
self.db_conn = pymysql.connect(host=host, port=port, db=db, user=user, passwd=passwd, charset='utf8')
self.db_cur = self.db_conn.cursor()
# 关闭数据库
def close_spider(self, spider):
self.db_conn.commit()
self.db_conn.close()
# 对数据进行处理
def process_item(self, item, spider):
if isinstance(item, TikuQuestions):
if spider.name == "tiku.answers":
self.update_questions(item)
elif spider.name == "tiku.yunxiao":
self.insert_into_questions(item)
###省略部分操作###
return item
def insert_into_questions(self, item):
"""插入试题表"""
values = (
item['question_id'],
item['q_period'],
item['q_subject'],
item['q_difficulty'],
item['q_type'],
item['q_from'],
item['q_year'],
json.dumps(item['q_refer_exampapers'], ensure_ascii=False),
json.dumps(item['q_knowledges'], ensure_ascii=False),
item['q_description'],
json.dumps(item['q_stems'], ensure_ascii=False),
item['q_comment']
)
try:
sql = """INSERT INTO questions (question_id,
q_period,
q_subject,
q_difficulty,
q_type,
q_from,
q_year,
q_refer_exampapers,
q_knowledges,
q_description,
q_stems,
q_comment)
VALUES(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
self.db_cur.execute(sql, values)
self.db_conn.commit()
except pymysql.err.IntegrityError as e:
pass
def update_questions(self, item):
"""更新试题表"""
answers = item['q_answers']
explanations = item['q_explanations']
solutions = item['q_solutions']
q_answers = json.dumps(answers, ensure_ascii=False)
q_explanations = json.dumps(explanations, ensure_ascii=False)
q_solutions = json.dumps(solutions, ensure_ascii=False)
try:
sql = """UPDATE questions SET q_answers='%s',q_explanations='%s',q_solutions='%s' where question_id=%s;""" % (q_answers, q_explanations, q_solutions, item['question_id'])
self.db_cur.execute(sql)
self.db_conn.commit()
except pymysql.err.IntegrityError as e:
pass如代码所示,实际业务中会有多个数据模型以及多个爬虫:
- 通过
if isinstance(item, TikuQuestions)定位当前的数据模型来源; - 通过
if spider.name == "tiku.answers"定位当前的爬虫来源; - 通过
if item['from_spider'] == "tiku.answers”定位当前的爬虫来源;
每个管道类中 return item 的意思是将处理过的item传给下一个管道类,如果不写return,那么下一个管道文件会处理空值;
将爬取的数据存入MongoDB
import pymongo
class MongoPipeline(object):
collection_name = 'scrapy_items'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert(dict(item))
return item数据去重
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item管道中的其他方法
open_spider(*spider*) 表示当spider被开启的时候调用这个方法;close_spider(*spider*) 当spider挂去年比时候这个方法被调用;from_crawler(*cls*, *crawler*) 这个可以用于获取settings配置文件中的信息,需要注意的这个是一个类方法,使用方法见 settings.py ;
注意:pipeline只在爬虫运行时实例化一次,把pipeline比作店员的话,一个pipeline便对应一个店员
settings.py
爬虫配置文件,在自定义爬虫中使用:
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
# 获取settings中定义的数据库参数
db = settings.get('MYSQL_DB_NAME')
host = settings.get('MYSQL_HOST')
port = settings.get('MYSQL_PORT')
user = settings.get('MYSQL_USER')
passwd = settings.get('MYSQL_PASSWORD')在middleware中使用时,除了上述引入 get_project_settings 模块,还可以:
- 通过形参
spider的spider.settings.get("配置或参数名"); - 通过
spider.settings["配置或参数名"]; - 通过
from_crawler类方法形参crawler的crawler.settings.get("配置或参数名");
P.S. 有关settings的详细说明,参考 这里
日志功能
- 在
settings.py中启用日志功能:
LOG_LEVEL = 'DEBUG' # 选择要输出的日志等级
LOG_FILE = 'log.txt' # 此时对应项目根目录,非settings.py的同级目录注意:开启log功能后,控制台不再输出内容,所有日志信息写入log.txt
- 在程序中输出日志,通过logging模块添加:
import logging
logging.warning("[警告信息]")
logging.error("[错误信息]")通过形参 spider 添加:
spider.logger.info('Spider opened: %s' % spider.name)P.S. 有关scrapy日志的更多信息,参考 这里
AUTOTHROTTLE
AUTOTHROTTLE翻译为智能节流,意思是可自动调节并发量,建议萌新开启;
项目记录
新建项目
- 使用Anaconda3 Navigator新建
scrapy虚拟环境; - 打开Anaconda Prompt切换
scrapy环境:
conda activate scrapyP.S. 如果要切换盘符,键入目标盘符如
d:,再使用cd到目标文件夹下;
- 到你喜欢的目录,输入以下命令以创建爬虫项目:
scrapy startproject <crawler name>- 经过上一步得到爬虫文件夹,移步到项目根目录继续添加爬虫模块:
cd <crawler name>
scrapy genspider <name> <domain>此处可选的爬虫模板可通过 scrapy genspider -l 命令查看;
项目文档
请求方式
通过分析,该网站可以直接调用,前提是得到登录后的cookie;
切换cookie
- 生成cookie方法,我采用登录后将cookie复制到txt文件中,一行即为一个用户的cookie:
import os
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
def check_cookies():
"""
检查本地cookie
:return: cookie
"""
cookies_list = []
with open(settings['WORKPATH'] + 'configs/cookie.txt', encoding='utf-8') as f:
lines = f.readlines()
for l in lines:
cookies = {}
for line in l.split(';'):
key, value = line.split('=', 1)
cookies[key] = value
cookies_list.append(cookies)
for cookie in cookies_list:
yield cookie- 调用cookie:
class AnswersSpider(scrapy.Spider):
name = 'tiku.answers'
allowed_domains = ['tiku.【数据删除】.com']
def __init__(self):
self.gen_cookie = check_cookies()
# 下略
def parse_answers(self, response):
json_text = response.text
try:
text = json.loads(json_text)
except json.decoder.JSONDecodeError:
logging.warning("***cookie失效,请重新获取***")
return
if text['code'] == 0:
item = TikuQuestions()
item['question_id'] = text['data']['id']
item['q_answers'] = text['data']['blocks']['answers']
item['q_explanations'] = text['data']['blocks']['explanations']
item['q_solutions'] = text['data']['blocks']['solutions']
yield item
elif text['code'] == 6:
logging.warning("此账号已达到当日浏览限制!")
try:
self.cookies = next(self.gen_cookie)
except:
logging.warning("cookie已使用完!")
# 强制退出爬虫
self.crawler.engine.close_spider(self, 'cookie已使用完!')
else:
yield scrapy.Request(response.url, callback=self.parse_answers, headers=settings.get("REQUEST_HEADERS"), cookies=self.cookies)self.crawler.engine.close_spider(self, 'cookie已使用完!')方法可在运行中强制退出爬虫,如果CONCURRENT_REQUESTS = 1立即退出,否则会重复提示n次;- 切换cookie
self.cookies = next(self.gen_cookie);
其实也可以像切换代理IP一样在middleware中实现;
请求payload
挺奇葩的请求方式,主要在分页请求中出现;
payload = {
"period": "{}".format(str(k[2])),
"subject": "{}".format(str(k[1])),
"knowledges": "{}".format(str(knowledge_id)),
"sort_by": "year",
"exam_type": "{}".format(exam_type),
"offset": 0,
"limit": 10,
"set_mode": {"knowledges": "union"}
}
js = json.dumps(payload) # 将payload转为字符串,其中的中文会转成ascii码
yield scrapy.Request("http://tiku.【数据删除】.com/kb_api/v2/questions/by_search", callback=self.parse_questions, cookies=self.cookies, body=js, meta={"payload": json.dumps(payload, ensure_ascii=False)}, method='POST', dont_filter=True, headers=settings.get("REQUEST_HEADERS"))时间转换
- ISO转datetime时间:
datetime.datetime.fromisoformat(text['data']['ctime'].replace("Z", "")).strftime("%Y-%m-%d %H:%M:%S")踩坑心得
- 在爬虫主文件中,如果需要递归操作,可以写成如下的闭包形式。之所以这样,怀疑是engine的锅导致不能在回调函数中调用其他函数:
def parse_knowledges(self, response):
"""
获取知识点详情
:param response:
:return:
"""
json_text = response.text
try:
text = json.loads(json_text)
except json.decoder.JSONDecodeError:
logging.warning("***cookie失效,请重新获取***")
return
with open(settings['WORKPATH'] + "save/books/book{0}.json".format(response.meta['book_id']), mode='w',
encoding='utf-8') as f:
f.write(json_text)
# 知识点详情
book = TikuBooks()
book['book_id'] = response.meta['book_id']
book['b_text'] = text['data']['book']
yield book
knowledges = text['data']['book']['children']
item_list = []
def get_knowledge(trees):
"""
递归寻找枝
:param trees: 非根节点
:return:
"""
for node in trees:
item = TikuKnowledges()
if node['key'] == 'chapter':
item['knowledge_id'] = node['id']
item['k_name'] = node['name']
item['k_node_key'] = node['key']
item['k_subject'] = text['data']['subject']
item['k_period'] = text['data']['period']
get_knowledge(node['children'])
elif node['key'] == 'knowledge':
item['knowledge_id'] = node['id']
item['k_name'] = node['name']
item['k_node_key'] = node['key']
item['k_importance'] = node['importance']
item['k_chance'] = node['chance']
item['k_subject'] = text['data']['subject']
item['k_period'] = text['data']['period']
item_list.append(item)
return item_list
for knowledge in get_knowledge(knowledges):
yield knowledge- 尽量不要在回调函数里进行数据库查询,可能会有item处理不及时导致数据丢失问题;
- 安装MySQL8.0.25后,出现“Exception: Current profile has no WMI enabled”错误解决方案_灰色芍药的博客-CSDN博客;
- windows下的scrapyd-deploy无法运行的解决办法_夏冬丶王阳旭-CSDN博客:
C:\ProgramData\Anaconda3\envs\scrapy\python.exe C:\ProgramData\Anaconda3\envs\scrapy\Scripts\scrapyd-deploy %*一些资源
IP代理网站
- 国内高匿免费HTTP代理IP - 快代理 (kuaidaili.com)
- 齐云 - 专业代理云服务供应商 (ip3366.net)
- 代理云 - 企业级分布式代理IP池PAAS平台|提供HTTP代理IP池租用与定制服务 (dailiyun.com)
- 星速云 - 爬虫Http(S)代理IP池,隧道代理,Http隧道,高匿名 (xingsudaili.com)
- 蜻蜓代理 - 企业级高质量代理ip平台 (horocn.com)
- 站大爷 - 企业级高品质Http代理IP_Socks5代理服务器_免费代理IP (zdaye.com)
验证码平台
- 暂无,后续更新…
我的常用User-Agents
USER_AGENT_LIST = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36",
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 ",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.41 Safari/535.1 QQBrowser/6.9.11079.201",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E) QQBrowser/6.9.11079.201",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36",
]参考链接
- Scrapy详解之中间件(Middleware) - 知乎 (zhihu.com)
- 彻底搞懂Scrapy的中间件(一) - 青南 - 博客园 (cnblogs.com)
- 爬虫框架Scrapy(三):Scrapy中的管道pipeline+下载中间件middleware_不愿意透露姓名的网友-CSDN博客
- requests.session()会话保持_学习python-CSDN博客_requests.session() -> 代理ip中间件
- 关于在scrapy中添加Request payload参数_一位不愿透露姓名的雷锋-CSDN博客
- 爬虫(三)scrapy的去重与过滤器的使用 - 知乎 (zhihu.com)
- 爬虫scrapy框架–log日志输出配置及使用_python爬虫人工智能大数据-CSDN博客
更多资源欢迎在评论区补充~
最后
目前项目还没用到可视化以及IP代理,有机会的话后续会更新本教程;
