
前言
最近在用Paddle做项目,原先的标注数据需要从hdict转到voc,顺手写一个转换工具…
正文
hdict结构
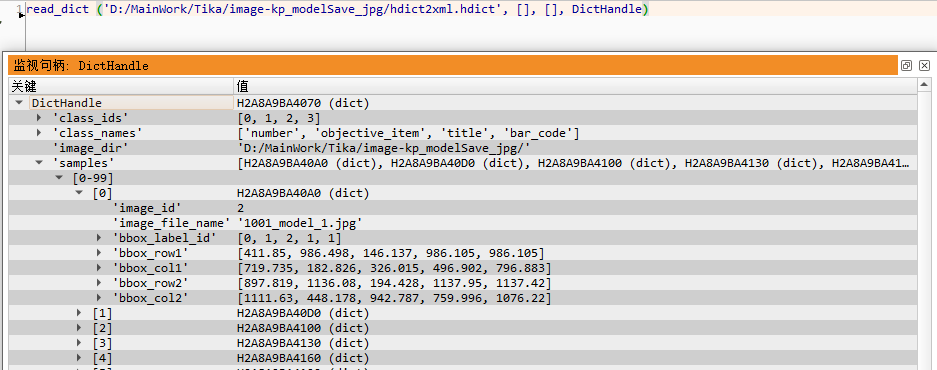
halcon数据集是通常是使用 MVTec Deep Learning Tool 标注,后缀名为 .hdict 的文件;
正如名字一样,它的结构类似python字典,需要使用
read_dict、get_dict_tuple算子读取数据;目前 MVTec Deep Learning Tool 支持图片分类、物体识别(轴平行矩形)、物体识别(自由矩形)数据集的制作;
voc结构
本次项目只涉及目标检测数据集,若为其他数据集,请自行搜索
voc数据集结构;你可能在别的地方发现xml文件包含其他字段,经过验证,仅本文出现的字段也能正常工作;
- Annotation文件夹
- xml文件
xml
<?xml version="1.0" encoding="utf-8"?>
<annotation>
<folder>VOC</folder> # 文件夹名
<filename>1481_model_2276_4250_1.jpg</filename> # 文件名
<size>
<width>3328</width> # 图片宽度
<height>2312</height> # 图片高度
<depth>3</depth> # 图片通道数
</size>
<segmented>1</segmented> # 是否用于分割,1有分割标注,0表示没有分割标注。
<object> # 分割区域
<name>number</name> # 区域类别
<truncated>0</truncated> # 目标是否被截断(比如在图片之外),或者被遮挡(超过15%)
<difficult>0</difficult> # 是否检测困难,0表示容易,1表示困难
<bndbox>
<xmin>571.815151515152</xmin> # 列1 column1
<ymin>267.781212121212</ymin> # 行1 row1
<xmax>1113.87575757576</xmax> # 列2 column2
<ymax>701.429696969697</ymax> # 行2 row2
</bndbox>
</object>
<object>
<name>title</name>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>92.009387016512</xmin>
<ymin>115.550893463017</ymin>
<xmax>1114.39346301742</xmax>
<ymax>259.59409635829</ymax>
</bndbox>
</object>
<object>
<name>objective_item</name>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>140.564615848601</xmin>
<ymin>1116.22411973158</ymin>
<xmax>381.658712206891</xmax>
<ymax>1267.41525295936</ymax>
</bndbox>
</object>
<object>
<name>objective_item</name>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>650.604878232677</xmin>
<ymin>1118.94266003167</ymin>
<xmax>899.491480057302</xmax>
<ymax>1271.46712659278</ymax>
</bndbox>
</object>
</annotation>- JPEGImages文件夹
- jpg文件
注意:
xml与jpg文件名要保持一致并且一一对应;
xml与jpg文件名不能含有中文、空格;
object中的name字段不能含有空格(也可能其他地方也不能,未验证);
图像需要是jpg格式;